Attention is all you need
@shubh_exists|Aug 26, 2025 (11m ago)174 views
This blog is a technical overview of the 2023 research paper about transformers architecture. Illustrations from Umar Jamil's video
Code reference to this blog can be found at - Github
Need of Transformers
RNNs had several disadvantages that the transformers architecture aimed to solve.
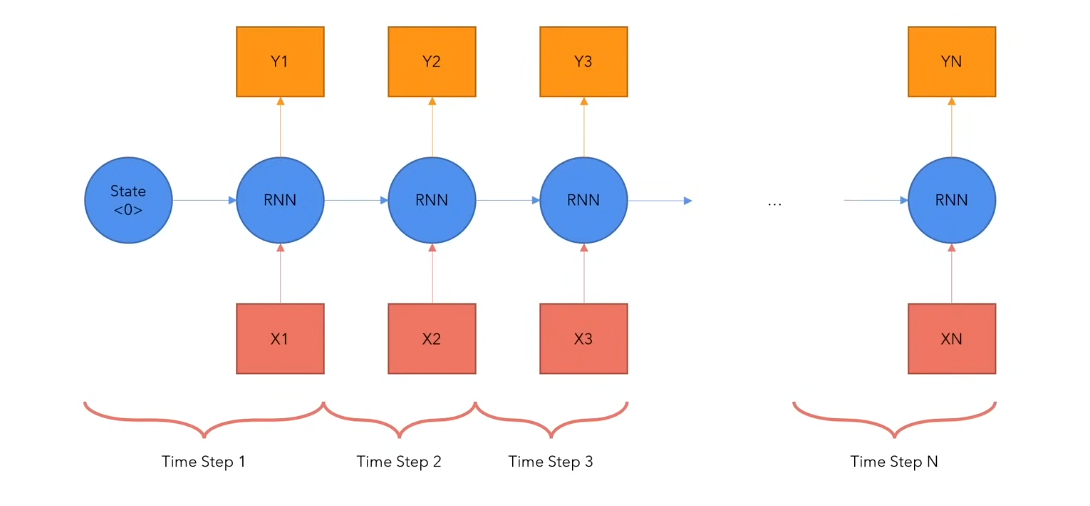
- Very slow for long sequences.
- It moves one step at a time so by the end of a sentence, the context of the starting words(tokens) is very less till the last.
Transformers
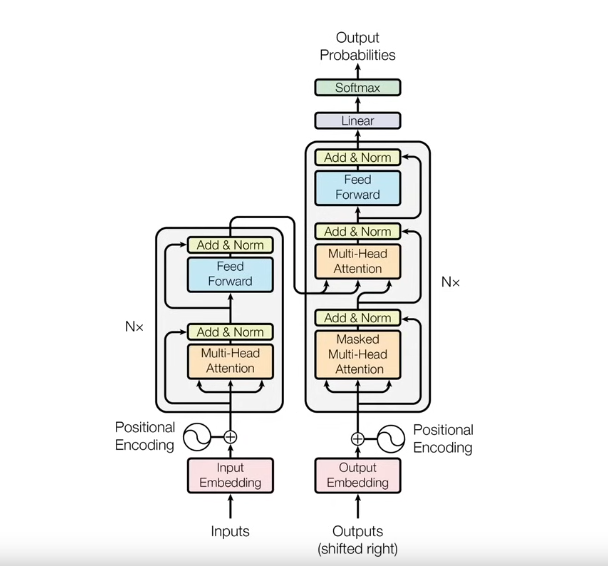
There are two major components of a transformer - Encoder and Decoder
1) Encoder
We have an initial fixed vocabulary where we assign a number to each word in our vocabulary based on their positions.
Input Embeddings
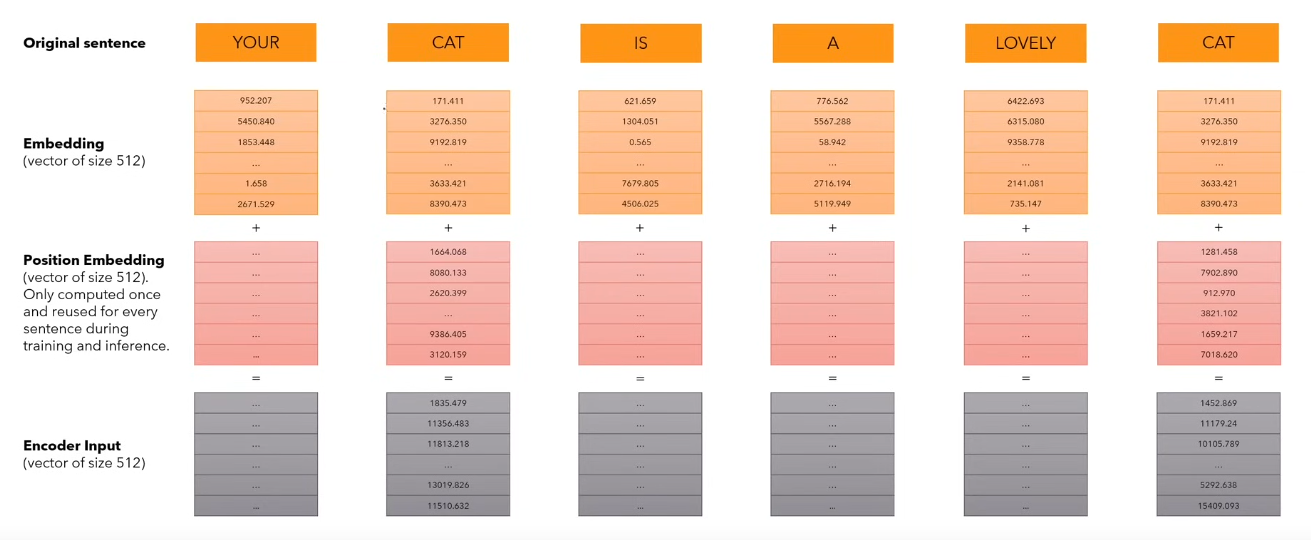
The input numbers/vocabulary is then converted into a vector of size dmodel which is 512 in this example.
Each parameter of the vector is variable and the model learns to tweak and change it during the training process to inculcate the meaning to the word.

Positional Encodings
This is a new vector that is added to each word in the sentence while training and inference to give the model an understanding of how close two words are in a sentence. We calculate Positional Encodings once in the start and then use the same values through out the training and the inference as these values remain the same throughout.
This new vector is of the same size of the word embeddings i.e. dmodel.
Calculations of positional encodings -
// For even positions in the vector of size dmodel
PE(pos,2i) = sin(pos/(10000^(2i/dmodel)))
// For odd positions
PE(pos, 2i + 1) = cos(pos/(10000^(2i/dmodel)))
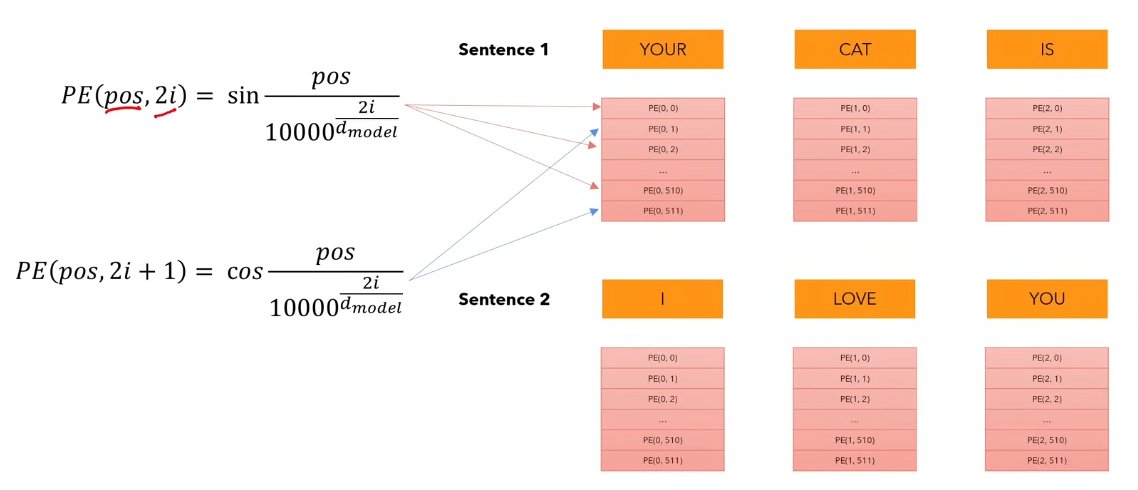
As you can see the values of the above sentence can easily be reused
throughout multiple sentences as positional encodings only depend on the
position and the dmodel. pos is the position of the word in the sentence and
i is the ith row i.e. embedding of that word.
Attention
Attention allows the model to relate words with each other. Before transformers, we used to have self-attentions but transformers introduced the term multi head attentions.
Attention(Q,K,V) = softmax(Q*K/(Dk^(1/2))) * V
- Self Attention
Imagine a sentence with 6 words (tokens) each with a vector of size dmodel (512). Q is the combination of these words to give us the sentence matrix of (6, 512) shape.
K is the transpose of Q since we are calculating the self attention, i.e. the attention of each word with each other word in the sentence.
We use the formula and calculate the softmax of the result.
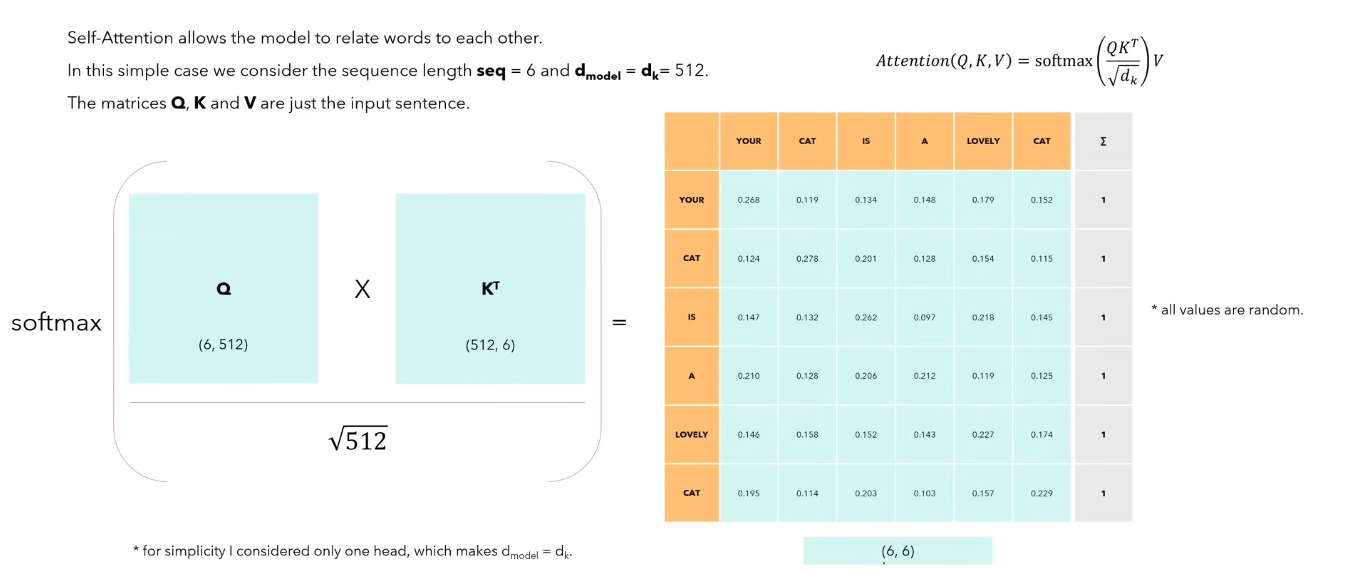
The sum of all the values in a row or column sum upto 1. Here the numbers represent how much close is a particular word to every other word in the sentence. Note that the diagonal has the highest number in every row as a word would be closest associated to itself.
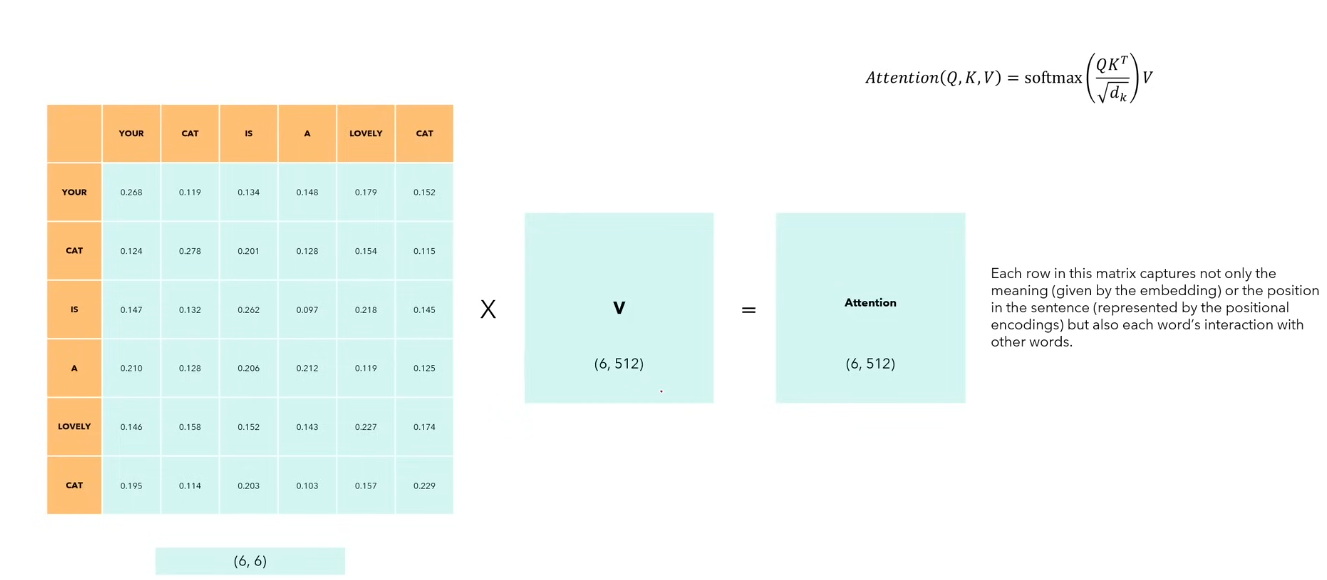
We finally multiply the final softmax result with V to get the attention matrix which is the same shape of the sentence Q. For self attention, V is equal to Q.
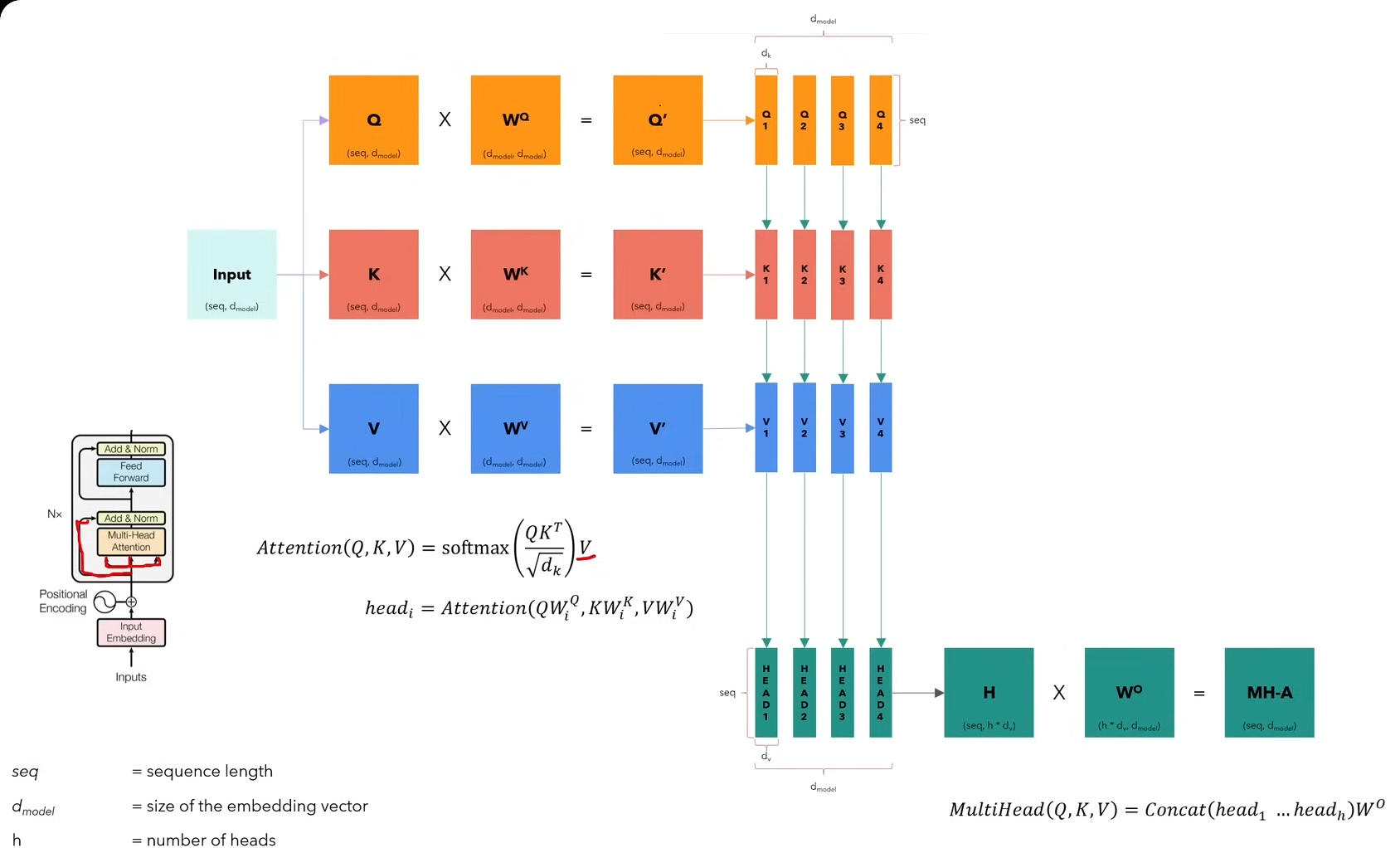
- Multi head attention
We make 3 copies of the input and then pass them individually through parameter matrices that are linear layers of size d_model * d_model. Each resultant matrix is divided into h heads and then, we have h parts of each Q, K and V.
We calculate the attention individually for each corresponding node and then the resultant will be concatenated the heads into a common matrix which is of the same size of seq * d_model.
Pass it through another linear layer and we get the final Multi Head Attention.
Layer Normalization
This is a process done to restrict the values in the vectors within 0 and 1. The main reason to do layer normalization is to Internal Covariate Shift. Suppose after backpropogation, the weights of layer 1 change a lot. The weights of layers after that would deviate a lot and the loss would increase. This would make the model training slow. Normalization prevents this.
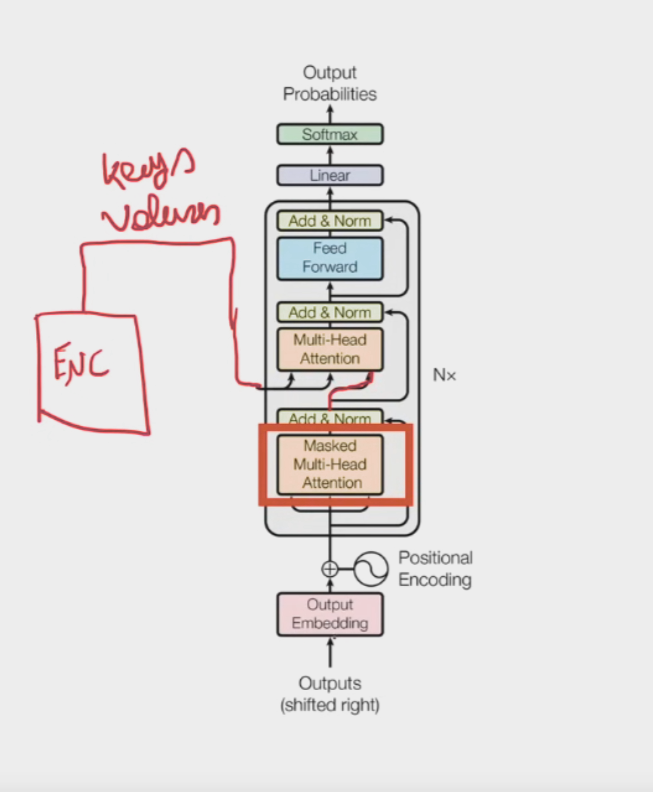
2) Decoder
Most of the blocks are similar to the encoder block.
In the multi head attention of the decoder, the key and the value comes from the encoder block, while the query comes from the embeddings of the output.
The linear and softmax after N attention blocks in the decoder, convert the embeddings back to the vocabulary number which is then converted to the text which that vocabulary represents.
Training
Note - While training, we mask out the attention of the words in the sentence that are ahead of the the word we are calculating for. We do this to prevent the influence of the future words of the sentence to make a impact on the attention score of a word.
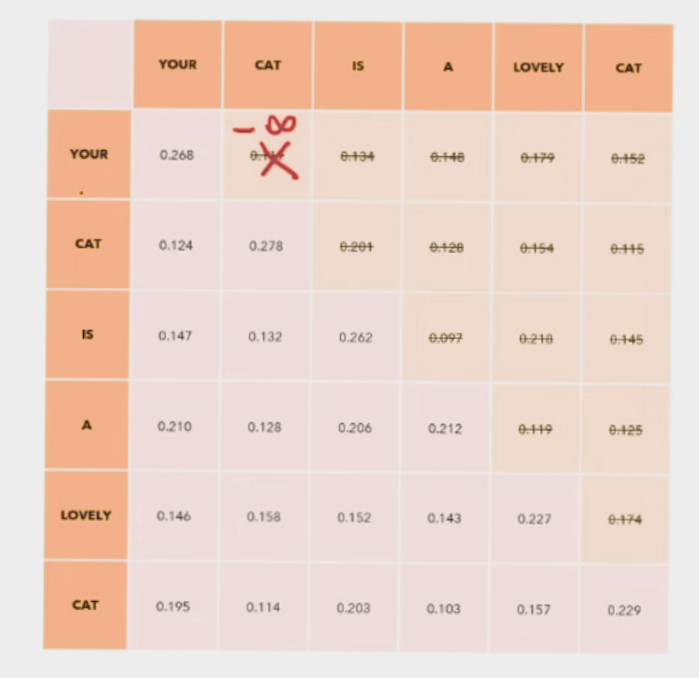
We make all the values above the diagonal as -infinity and since Softmax is
e^x, e^-infinity will be 0, thereby masking all the future values.
We first take the input sentence, append special tokens <SOS> and <EOS> in the sentence, and then we will calculate the attention values of the input text.
Since we are training, we will know the output text also. We will start with <SOS> {output_text} and then run the decoder with the encoder values. The output of running the entire cycle should be
{output_text} <EOS>. We would callculate the loss, backpropogate and then continue with the next data.
Note that we did the complete process in just one step instead of multiple single word loops in a RNN.

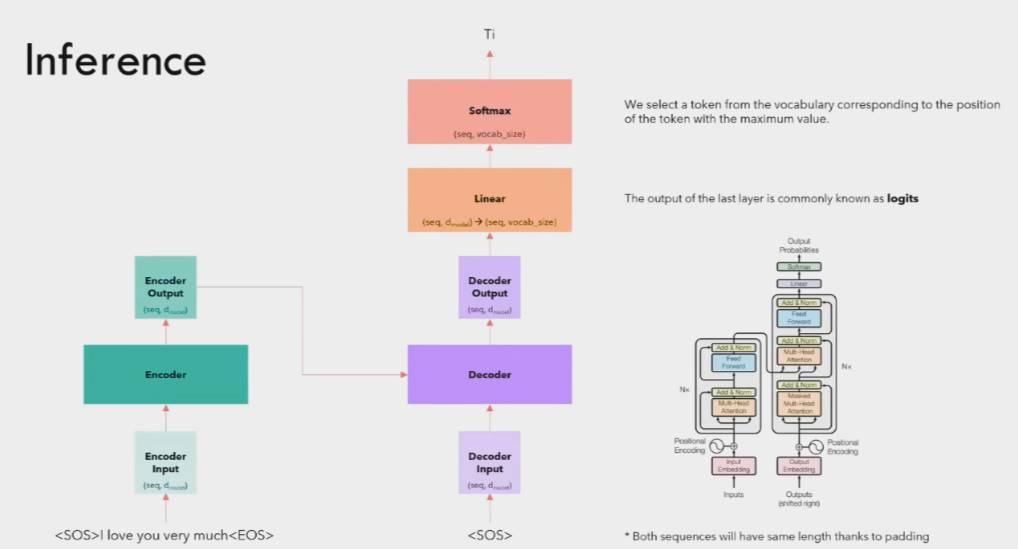
Inference
Inference of a transformer is a loop process. We keep on looping this the transformer returns a <EOS> token.
The user provides the text that the model is querying from, so the text remains the same throughout the query, hence we calculate the input embeddings and attention once in the starting and then reuse the same embeddings throughout.
The output embedding is to be determined, hence the starting output embedding is <SOS> token. The output of the 1st loop should be the 1st word of the response.
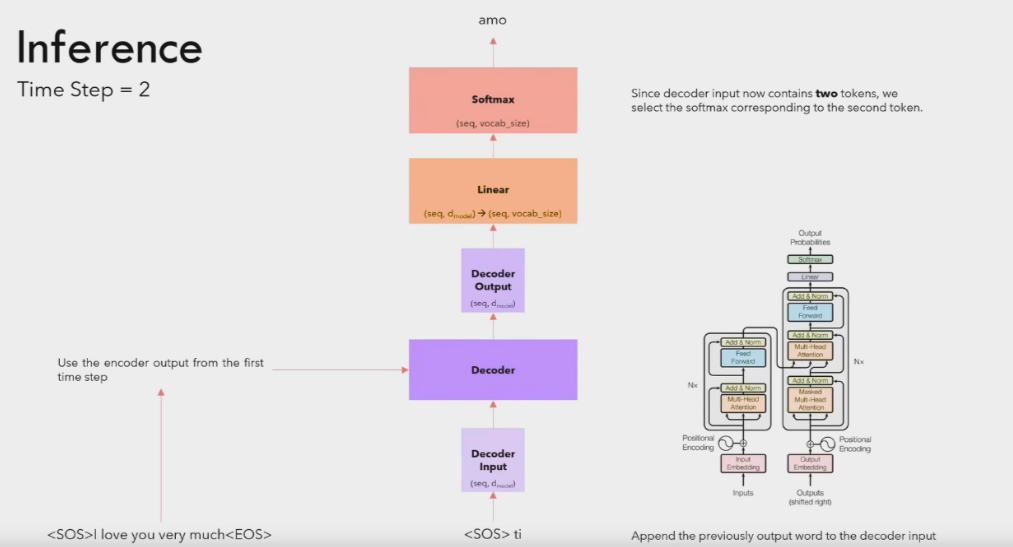
The output of the previous loop is appended to the main output string and then is passed to the transformer again.
This process continues till we get a <EOS>. We stop at EOS and return the response.
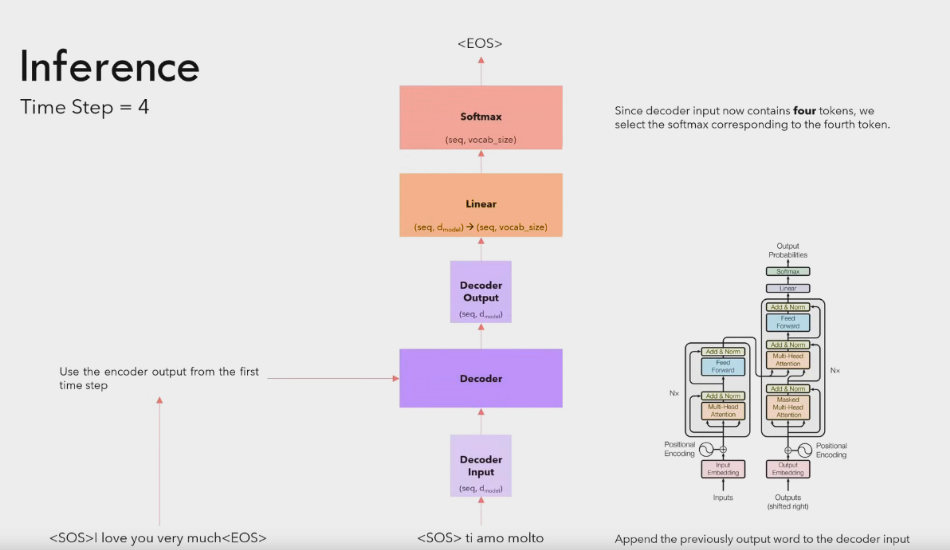
The above strategy is called greedy where we just take the most rated word out of the decoder at each step. We can also use Beam search where we take the top B words from the Softmax and use them to calculate the next words for each of the B words. This way we can reduce overfitting. This is how
tempratureparameter is controlled in the model.